

Research assignment
Terms used in this document
- brand
- A Brand is an entity that represents the manufacturer or supplier of the product. Brands are often a key factor driving customers' choice process. E-commerce sites provide information about the brand in the product detail and very often provide specialized brand pages with all products of a brand with additional information about the manufacturing process, quality assurance and other marketing information.
- cart
- A cart is a place where items selected by a customer for later purchase are collected. The cart is an important part of each e-commerce application but since it's specific to the e-commerce store, there's no special support in evitaDB.
- category
- A category is an entity that forms a hierarchical tree and categorizes items on the e-commerce site into a better accessible form for the customer. A category in a store with electronic products may be Computers, which has sub-categories Laptops, Game consoles, Desktops and so on. It is common upper categories on e-commerce sites display items placed in all its sub-categories. In our example it means that in the category Computers, the customer will see either laptops, game consoles or desktops all at once.
- complex entities
- Complex entities are entities that represent a bulk of other entities. On example is parametrized product - i.e. a product with several variants when only variant can be bought. A real life example of such parametrized product is a T-shirt that has several sizes (S, M, L, XL, XXL) and different colors (blue, red). You want the T-shirt to be represented as single product in e-commerce listing and variant selection is performed at the moment of the purchase. Different variants of this shirt may have different prices so when filtering or sorting we need to select single price that will be used for parametrized product. For such case FIRST_OCCURRENCE inner entity reference handling strategy is the best fit (see PriceInnerEntityReferenceHandling). A different example of a complex entity is a product set. A product set is a product that consists of several sub products, but is purchased as a whole. A real life example of such product set is a drawer - it consists of the body, the door and handles. The customer could even choose, which type of doors or handles they want in the set - but there always be some defaults. Again, we need some price assigned for the product set for the sake of a listing (i.e. filtering and sorting) but there may be none when the price is computed as an aggregation of the prices of sub-products. In case this happens, the SUM inner entity reference handling strategy is the best fit (see PriceInnerEntityReferenceHandling).
- facet
- A facet is a property of the entity that is used for quick filtering entities by the customer. It is represented as a checkbox in the filtering bar or as a slider in case of a large number of distinct numeric values. Facets help customers to narrow their listing of current category, manufacturer listing or the results of the fulltext search. It would be hard for the customer go through dozens of pages of results and probably would be forced to look for some sub-category or find a better search phrase. That's frustrating for the user and facets could ease this process. The user can narrow the results by a few clicks on relevant facets. The key aspect here is to provide enough information and require to guide user to most relevant facet combinations. It's very helpful to disregard facets as soon as they would cause no results to be returned or even inform the user that selecting a particular facet would narrow the results to very few records and that their freedom of choice will be severely affected.
- facet group
- A facet group is used to group facets of the same type. Facet groups control the mechanisms of facet filtering. It means that facet groups allow defining, whether facets in the group are combined with a boolean OR, AND relations when used in filtering. It also allows defining how this facet group will be combined with other facet groups in the same query (i.e. AND, OR, NOT). This type of boolean logic affects the statistics computation of the facets and is the crucial part of the facet evaluation.
- fulltext search
- Fulltext search is a process when user tries to locate an appropriate product/category/brand (or any other entity) by specifying a search phrase. The problem is that user expects fulltext results to be as accurate as Google provides in its search. Achieving a similar quality in e-commerce application is a really hard task that requires both, a top-notch fulltext engine and some form of self-learning algorithms (AI).
- group
- A group is an entity that references a set of products by some cross-cutting concert. As an example of groups, you can imagine: top products (displayed on the homepage), new products (last X products added to an inventory), gifts and so on. Groups are versatile units to display a bunch of products on different places of the web application.
- product
- A product is an entity that represents the item sold at an e-commerce store. The products represent the very core of each e-commerce application.
- product with variants
- A product with a variant is a "virtual product" that cannot be bought directly. A customer must choose one of its variants
instead. Products with variants are very often seen in e-commerce fashion stores where clothes come in various sizes
and colors. A single product can have dozens combinations of size and color. If each combination represented standard
product, a product listing in a category and other places would become unusable.
In this situation, products with variants become very handy. This "virtual product" can be listed instead of variants
and a variant selection is performed at the time of placing the goods into the cart. Let's have an example:
We have a T-Shirt with a unicorn picture on it. The T-Shirt is produced in different sizes and colors - namely:
– size: S, M, L, XL, XXL
– color: blue, pink, violet
That represents 15 possible combinations (variants). Because we only want a single unicorn T-Shirt in our listings, we create a product with variants and enclose all variant combinations to this virtual product. - product set
- A product set is a product that consists of several sub products, but is purchased as a whole. A real life example of such
product set is a drawer - it consists of the body, the door and handles. A customer could even choose which type of doors
or handles they want in the set - but there always be some defaults.
When displaying and filtering by a product set in the listings on the e-commerce site, we need some price assigned for it but there may be a none exact price assigned to the set and the e-commerce owner expects that price would be computed as an aggregation of the prices of sub-products. This behaviour is supported by setting proper PriceInnerEntityReferenceHandling. - property
- An entity that represents an item property. Properties are handled as top entities, because we expect that properties may have
additional attributes and localizations to different languages. Properties are usually referenced in other items'
facets. Properties are usually composed of two parts:
– property group, referenced in facet group, fe. color, size, sex
– property value, referenced in facet, fe. blue, XXL, women - variant product
- A variant product is a product that is enclosed within a product with variants and represents a single combination of a particular product. In case of the example used in a referenced chapter, it would be, for example, the Unicorn T-Shirt, pink, M size.
This document uses the future tense because it was originally written at the beginning of the project. The research phase of the project has now ended, so the future tense does not make sense now, but we have made only minimal changes to the text to preserve the original ideas and tone. Notes and references have been added at some points in the document to refer to a specific part of the research already conducted.
Research procedure
All competing solutions will be populated using a data pump with real datasets (both from B2C and B2B environment) of existing FG Forrest clients, who gave their explicit consent to do so. The client data sets will not contain any personal data - it will only represent a "sale catalog".
Evaluation methodology
A single, automated test suite will be implemented that will test all of the basic scenarios from a real-life e-commerce solution. This suit will then be run against individual implementations in a lab environment and the results will be recorded.
The criteria for evaluating the best option are:
- cumulative response speed in the test scenarios (weight 75%)
- memory space consumption (weight 20%)
- disk space consumption (weight 5%)
The cumulative response time to (at least) all subsequent search queries is measured on:
- category tree display (open to the current category) - menu rendering
- category detail display (retrieving one full category entity) + product listing
- product listing filterable by
- parameters
- brands
- tags
- prices
- product ordering
- by selected attribute
- by price
The cache utilization is problematic in a filtering scenario, because there are way too many combinations the user can select. Moreover, the data is frequently changed due and the impact of these changes, it is hard to translate to cache record invalidation orders, because of the complex relations between them. The implementations thus can't rely on the caching layer when the tests are run and the performance is evaluated.
Expected record counts for performance tests
Entities
Our performance tests are run on data sets that are similar to these:
| Entity | Senesi.cz | Signal-nabytek.cz | Fjallraven CZ | Rako CZ | Kili CZ |
|---|---|---|---|---|---|
| adjustedPricePolicyToggle Term Reference | 2 | 2 | 3 | 1 | 110 |
| brandToggle Term Reference | 158 | 42 | 0 | 0 | 76 |
| categoryToggle Term Reference | 202 | 220 | 87 | 16 | 325 |
| groupToggle Term Reference | 1190 | 20 | 7 | 1 | 265 |
| parameterItemToggle Term Reference | 19299 | 3477 | 1346 | 2044 | 2848 |
| parameterTypeToggle Term Reference | 255 | 558 | 32 | 48 | 39 |
| paymentMethodToggle Term Reference | 15 | 4 | 3 | 1 | 5 |
| priceListToggle Term Reference | 2 | 3 | 6 | 4 | 7044 |
| productToggle Term Reference | 64628 | 50852 | 31144 | 3587 | 26567 |
| shippingMethodToggle Term Reference | 3 | 15 | 6 | 1 | 52 |
Legend
- entity: adjustedPricePolicy
- price policy (discounts, special programs and so on)
- entity: brand
- brand (such as: Nokia, Samsung and so on)
- entity: category
- product category (such as: TV, Notebook and so on)
- entity: group
- product groups (such as: action ware, new items on stock and so on)
- entity: parameterType
- parameter facet group detail data (such as: color, size, resolution)
- entity: parameterItem
- parameter facet detail data (such as: blue, yellow, XXL, fullHD)
- entity: paymentMethod
- form of paying on the site (such as: by credit card, direct transfer and so on)
- entity: priceList
- entity aggregating prices of product sharing common trait (such as: VIP, sellout)
- entity: product
- entity that is being sold on the site
- entity: shippingMethod
- form of delivery of the goods (such as: DPD, PPL, Postal service and so on)
Connected data cardinalities:
| Type of data | Senesi.cz | Signal-nabytek.cz | Fjallraven CZ | Rako CZ | Kili CZ |
|---|---|---|---|---|---|
| price | 68522 | 59018 | 193680 | 15885 | 1594502 |
| associated data | 479246 | 326205 | 209694 | 23535 | 298963 |
| localized texts | 258798 | 353597 | 88913 | 94803 | 102855 |
| attributes | 1351227 | 924281 | 574488 | 66820 | 572674 |
| facets | 876080 | 802583 | 334008 | 144161 | 466160 |
Localized texts are a part of associated data and they are counted separately, so that Evita knows how big of a part they play in the associated data set. Localized texts are not counted in the associated data row.
Validation set
In the initial phase, the university teams will select one general-purpose relational database and one NoSQL database. The criteria for selecting a database machine is:
- the license to run the e-commerce platform must be free of charge
- the database resource must have good documentation
- the database is expected to be further developed or supported in the next 5 to 10 years
- it can run on Linux OS (ideally Ubuntu distribution)
Recommended technologies to start investigation are (the selected set is not complete and can be extended by another database engine):
- relational database candidates:
- NoSQL database candidates:
Custom "greenfield" solution
The solution will be designed as an in-memory NoSQL database optimized to run on a single machine. The cluster mode will be designed as single writer, multiple reader replicas with the same dataset, which will be updated using an event stream from the primary source of truth.
The API and implementation will be designed so that as many related operations as possible are computed within a single request using common intermediate results. The client will not have to compose the functionality with a large number of database engine calls (in current solutions it is common for dozens of calls to a generic database engine to be needed to display category details with product listings).
Developing solutions for practical applicability
Based on the measurements, the best implementation option is selected and refined to production quality, which requires extensive and clear documentation, coverage of automated units, integration and performance tests.
The goal is:
- to prepare HTTP APIs for communication with the outside world using commonly used formats:
- containerization of the distribution package (using Docker)
- extending the implementation to a clustered solution (required on all major e-commerce sites)
- publishing source files on generally accepted hosting platforms (GitHub, Gitlab or BitBucket)
- API documentation
- implementation of a sample e-commerce solution on top of this API with a basic dataset in JavaScript / Node.JS
Data model
See a more detailed [API schema(updating/schema_api), describing the data model manipulation.
Entity type
Although evitaDB requires a schema for each entity type, it supports automatic evolution when you allow it. If you don't specify otherwise, evitaDB learns about entity attributes, their data types and all necessary relations along the way when you insert new data into it. However, once the attribute, associated data or other contours of the entity are known, they are enforced by evitaDB. This mechanism somehow resembles the schema-less approach, but results in much more consistent data store.
Primary key
May be left empty if it should be automatically generated by the database. The primary key allows evitaDB to decide whether the entity should be inserted as a new entity, or an update to an existing entity.
Hierarchical placement
Entities may be organized in a hierarchical fashion. That means that an entity may refer to a single parent entity and may be referred to by multiple child entities. A hierarchy is always composed of entities of the same type.
Each entity must be part of, at most, a single hierarchy (tree).
Most of the e-commerce systems organize their products in a hierarchical category system. The categories are source for the catalog menus and when the user examines the category content, they usually see the products in the entire category subtree of the category. That's why the hierarchies are directly supported by evitaDB.
Attributes (unique, filterable, sortable, localized)
Entity attributes allow defining sets of data that are fetched in bulk along with the entity body. The attribute may be marked as filterable to enable filtering by it, or sortable to be sorted by it. The attributes are not automatically searchable / sortable in order to not waste precious memory space and save computational overhead for maintaining and an index for the data that will never be used in queries.
Attributes must be used for all of the data you want to filter or sort by. Attributes are recommended to also be used for frequently used data that are associated with the entity (for example "name". "perex", "main motive") even if you don't necessarily need it for querying purposes.
Allowed decimal places
When a number cannot be converted to a compact form (for example it has more digits in the fractional part than expected), an exception is thrown and the entity update is rejected.
Localized attributes
Data types in attributes
Associated data
Localized associated data
References
Prices
Prices are specific to very few entity types (usually products, shipping methods and so on), but because correct price computation is very complex and an important part of the e-commerce systems and highly affects performance of the entities filtering and sorting, they deserve first class support in entity model. It is pretty common in B2B systems for a single product to have dozens of assigned prices for different customers.
Entity indexing
Bulk indexing
Bulk indexing is used for rapid indexing of large quantities of source data. It's used for initial catalog setup from an external (primary) data store. It doesn't need to support transactions. Whenever something goes wrong, the work in progress might be thrown away entirely without affecting any clients (because it's initial DB setup, no client is reading from it yet). The goal here is to index hundreds or thousands entities per second.
Bulk indexation is executed in single-threaded fashion.
Incremental indexing
Rolled back transaction must not affect the working data set. Committed transaction must leave data set in a consistent state and must be resistant to unexpected process termination or hardware failure (committed data should enforce fsync to a persistent disk storage).
Data fetching
The client application can request for the returning entity bodies instead, but this must be explicitly requested by using a specific require constraint:
Lazy fetching (enrichment)
This process loads the above-mentioned data separately and adds them to the entity object anytime after it was initially fetched from evitaDB. Due to the immutability characteristics enforced by the database design, the entity object enrichment leads to a new instance.
Lazy fetching may not be necessary for a frontend designed using the MVC architecture, where all requirements for the page are known prior to rendering. But different architectures might fetch thinner entity forms and later discover that they need more data in it. While this approach is not optimal performance-wise, it might make the life for developers easier, and it's much more optimal to just enrich an existing query (using lookup by primary key and fetching only missing data) instead of re-fetching the entire entity again.
Query requirements
Querying is the heart of all databases, and therefore, the core of the query language was designed upfront in the prototype implementation phase along with the unified functional test suite. When the first versions of the prototype implementations were created, the functional suite also accompanied the performance test suite, first for the artificial data set, and later, for real customer data sets.
Attributes
- numeric: equals, greater than, lesser than, between, in range
- temporal: equals, greater than, lesser than, between, in range
- string: contains, starts with, ends with
- boolean: is null, is not null
Localized search
- Product A: EN, CZ, IT
- Product B: EN, DE, FR
- Product C: EN, CZ, PL
Parameters (faceted search)
- discrete constants (for example color:black, size:XXL, OS:Android) visualized as checkboxes or selects
- or numeric values that are spread out in some range and can be visualized as a slider with min and max boundaries
For better customer orientation on how a certain facet narrows the item listing e-commerce sites display or the number of the items that have a certain property next to it - see this example (numbers in brackets):
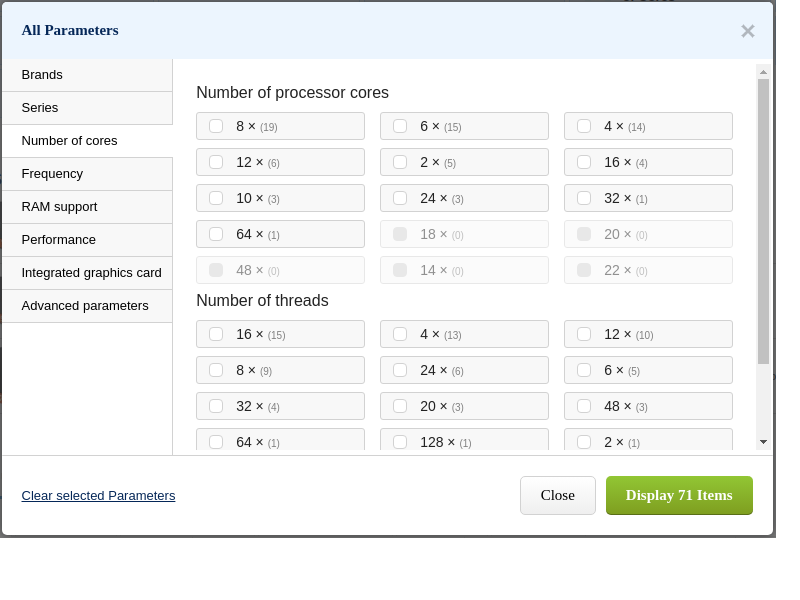
An even better approach is to reflect the currently selected filter in the faceted filter itself. Additional facets that would return no result if selected are displayed as disabled (see grayed properties with zero brackets in above example).
Interval properties
E-commerce filters contain not only facet,s but also sliders that allow the user to search for items having the attribute in a certain value range. For example, when you buy a refrigerator, you are usually constrained by the space at your disposal, and you need to set limits for the width, length and height of the refrigerator.
Example:

- return thresholds for each interval property (stored as entity attribute):
- highest value of the property in the item view
- lowest value of the property in the item view
- optionally: compute the histogram of describing attribute values computed from the items in this view (i.e. threshold with a count of items having this property in a respective histogram interval)
Inverted relations
Facets in the same facet group are usually combined by a boolean OR (disjunction) relation and facets in different groups are combined by a boolean AND (conjunction) relation. These relations might be inverted in some edge cases and the database must support the definition of inverted relations among facet groups and the facets within a certain group.
Negative properties
Some facets might have a negative meaning - so that if a user marks them, they expect that listing to only contain items that don’t have such property (as an example consider this facet: allergen:gluten which will cause that all items containing gluten will be removed from the listing).
- EXCLUDE all items having such property from the result
- properly compute the number of selected records
Impact statistics
Facets that would further expand count of the matching items (if selected) display difference count with the plus sign, or the updated overall result count next to them. See example below (numbers in brackets):

- return extended statistics computed for all other facets that contains information about:
- how many items are added to result if facet would be added to filtering
- how many items are removed from result if facet would be added to filtering
- how many items remain in the result if facet would be added to filtering
- correctly apply OR / AND / NOT relations defined by property groups
Prices
For master products, the lowest price of any product variant is used. For complete sets, dual behaviour must be supported:
- if a price is set directly for a set, count with this price
- if not, the most preferred price for each item of such a set must be added up and the resulting amount calculated
Price histogram
Brands / groups
The number of products of a given brand in the categories
Tags
Fulltext search
The solution should allow to easily combine full-text search with parametrized (faceted search). Fulltext search may not be implemented initially, but should offer a mechanism for integration of an external fulltext system.
Hierarchical search and tree exclusion
- match the basic attribute predicate: for example, those are marked as visible, are valid for display at that certain moment in time etc.
- contain at least one visible product in any child level, the product must:
- match an independent attribute query
- match the requested locale
- produce a price for sale
- compute the overall count of all items available in this entity (categoryToggle Term Reference)
- items that have an invisible parent (categoryToggle Term Reference that doesn't match its own predicate) must not be counted
- a single item (productToggle Term Reference) may relate to more than one hierarchical parent (categoryToggle Term Reference), the fact that a product is not counted in one category axis must not affect the other visibility axis
- counts of lower level nodes are automatically counted in the overall count of their parent category
- produce a result in a tree-like structure friendly for rendering
Product sorting
The search engine must be able to sort results by:
- attribute: for example, the number of stars, number of sales
- multiple attributes: there are special cases where one attribute contains less selective values and another attribute is required for predictable search results
- price for sale: cheapest, most expensive
Personalized sorting
As a part of the research, it would be useful to look at the possibilities of personalized sorting, which would allow a user to be presented with the results that are likely to be of interest to them first, based on their previous experience with that user (i.e., based on their previous purchases or visits).
For this purpose, it will probably be necessary to use one of the "shallow" artificial intelligence (machine learning) algorithms and construct a personalised search index in such a way that the search is not slowed down.
This functionality is not critical to the evaluation of the winning approach - it is an add-on functionality that no existing database currently includes as part of its functionality. However, we know that global trends are moving in this direction.