

Testable documentation
This article is a continuation of a series of articles about the documentation portal of our database. This time we will look at it from a different point of view - from the perspective of the developer who creates the documentation, and whose interest is that the documentation written is correct and does not become outdated over time.

The technical documentation written by evitaDB developers requires a different approach than the documentation written by marketing or sales people. Developers are tied to their integrated development environment (IDE) and want it to be close and interlinked with the source code they are working on. They don't want fancy editors or to spend too much time on styling - plain MarkDown is usually the best choice for them. What they want is to have the documentation in the same repository as the source code, so that they can easily create a pull request and have the documentation reviewed by their colleagues. And they want to have the documentation reviewed, so that they can be sure that the documentation is accurate and up to date.
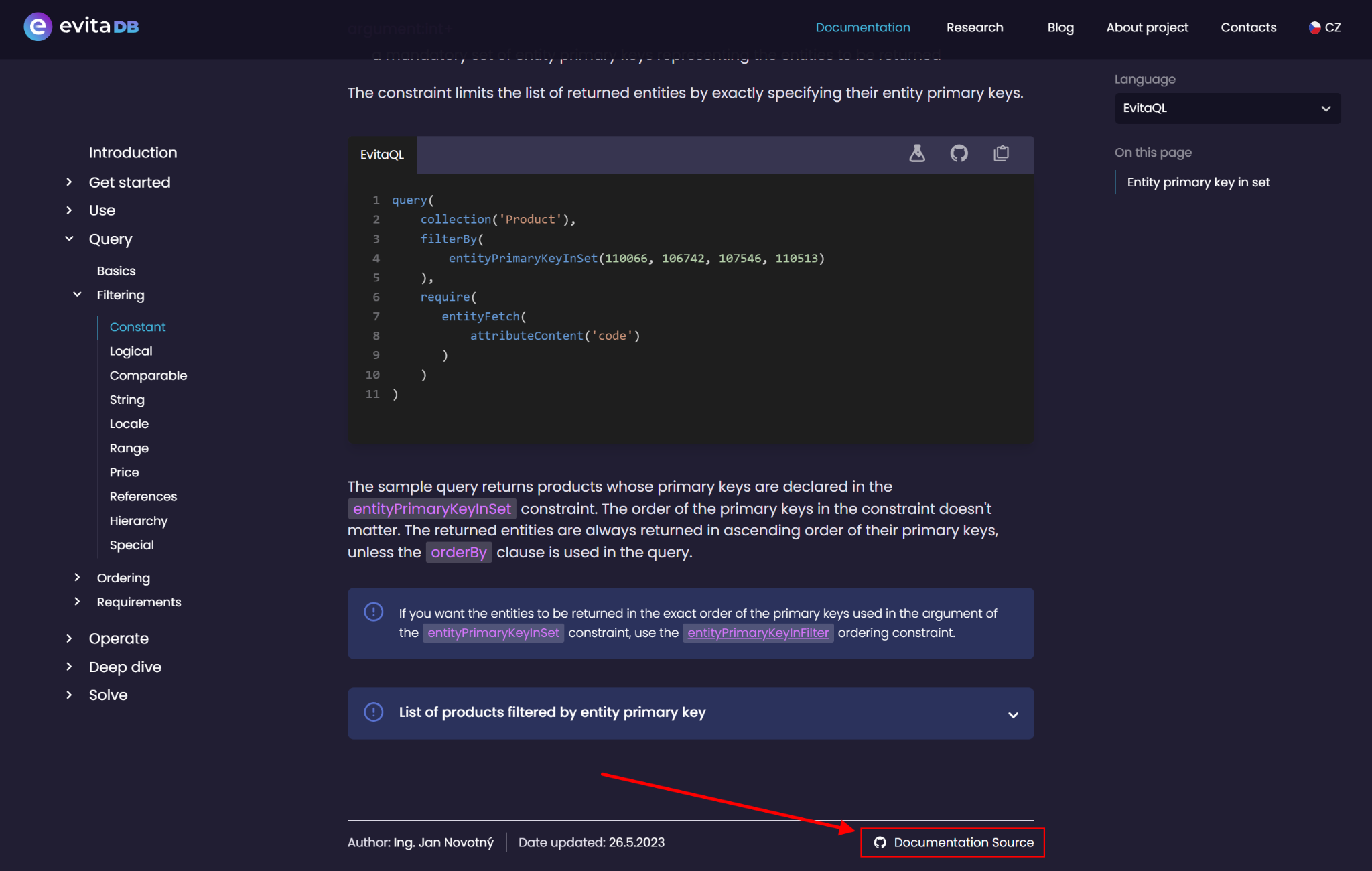 Documentation on portal
Documentation on portal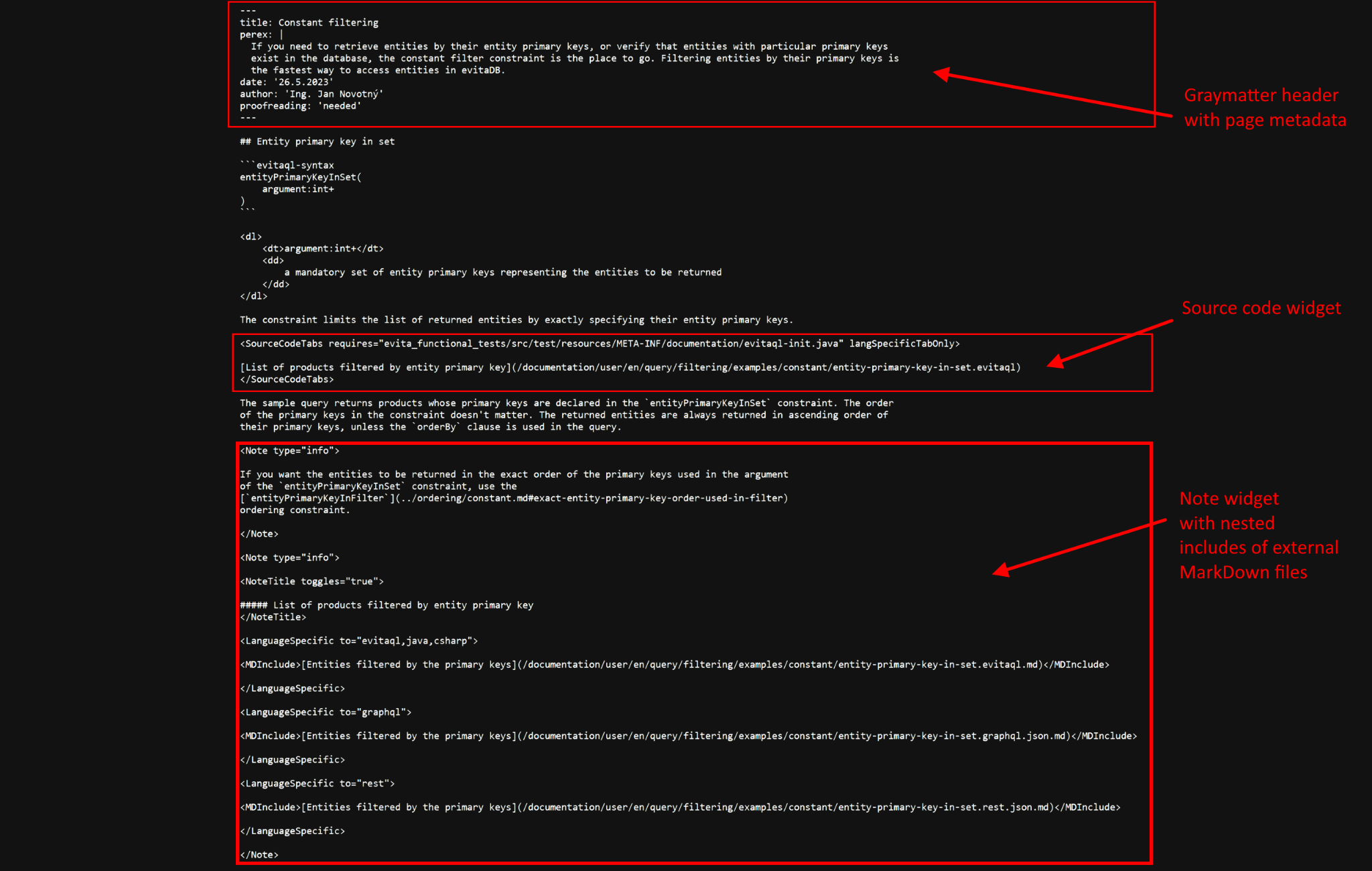 Source MarkDown format
Source MarkDown formatThis combination allows us to make documentation interactive on our documentation portal, without preventing it from being displayed correctly in GitHub or other MarkDown viewers.
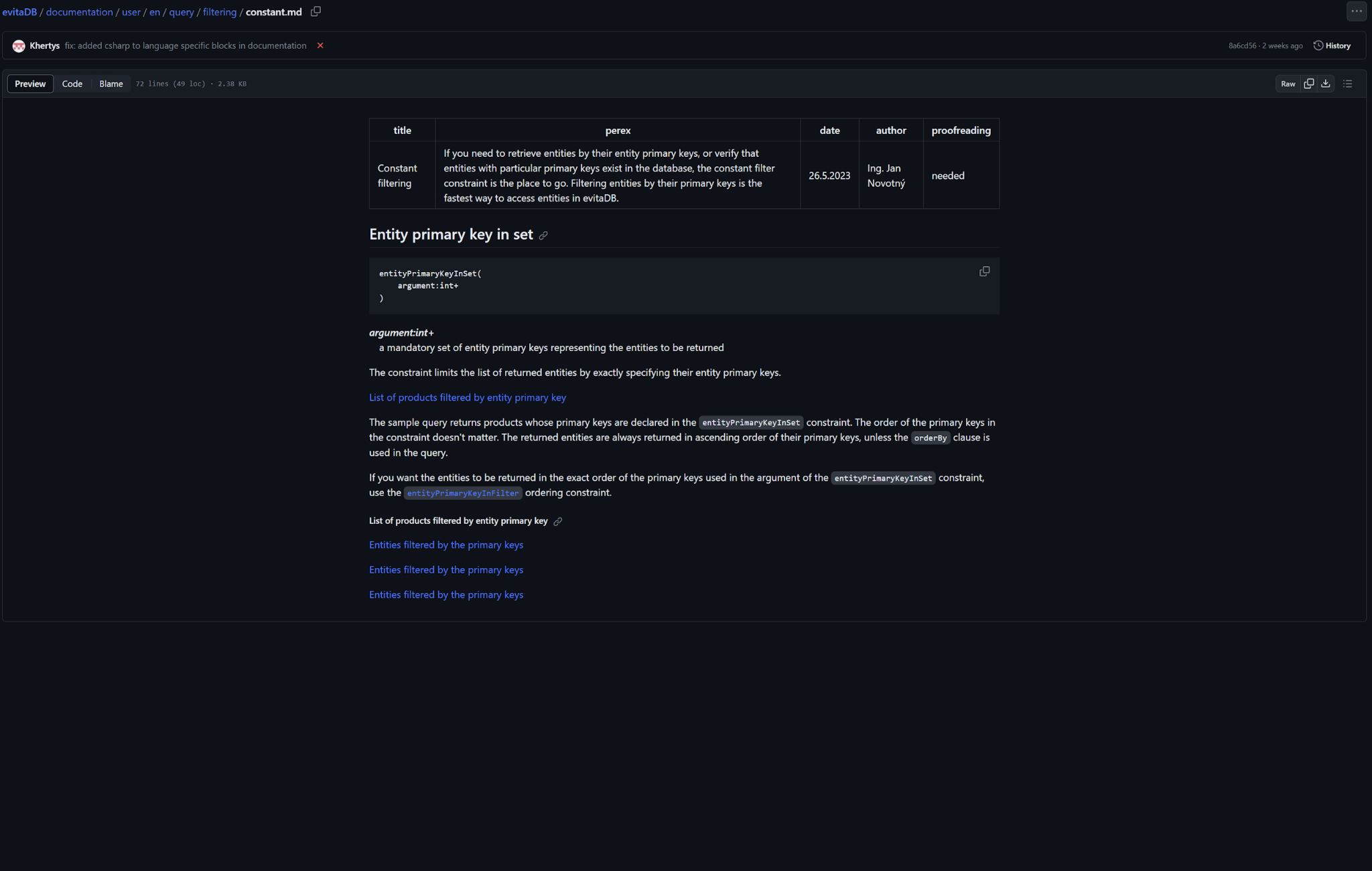 GitHub view
GitHub viewThe documentation contains a lot of code examples that we need to keep up to date, compilable, executable and tested. We decided to organise the documentation according to the environment / programming language the user will interact with our database. This means that we have to port all the examples into several consumer languages - evitaQL, GraphQL, REST, Java or C#.
 Language selector
Language selectorTesting and verification
OK, we have written the documentation, we have generated the examples, but how can we be sure that the examples are correct? We need to test them regularly and check that they still produce the same results as when they were written. In this way we can also test the availability and correctness of the demo dataset, which is not entirely static, but also changes over time.
However, testing is quite a challenge. Each platform/language requires a different way of running the examples. Let's have a look at each of them:
- The Java examples were quite challenging and their testing was documented in the previous blog post
- evitaQL uses Java Client
- REST API uses simple HTTP client to make requests
- GraphQL API uses simple HTTP client to make requests
- C# examples use C# Client
Obstacles overcome
Lunch was not free. We had to overcome some obstacles to make it work. Let's have a look at them:
MarkDown rich widget notation
We have tried to stick as closely as possible to the standard MarkDown notation, but have had to extend it a little to allow examples to be written in multiple languages. We take advantage of custom tags, which are then processed by our React components, but ignored by other MarkDown renderers such as GitHub. The design of all tags requires careful consideration and formatting.
Github rate-limiting
Links
Because the structure of the repository is different from the structure of the documentation portal, we had to implement special logic that translates the links in the documentation to the correct location relative to the documentation portal. We also identify the links that point to external resources and mark them with a special icon.
All links are designed to work in the evitaDB GitHub repository, and the documentation portal has to translate them to the correct location.
C-Sharp client
Component & activity pseudo-diagram
The entire setup can be summarised in the following diagram:
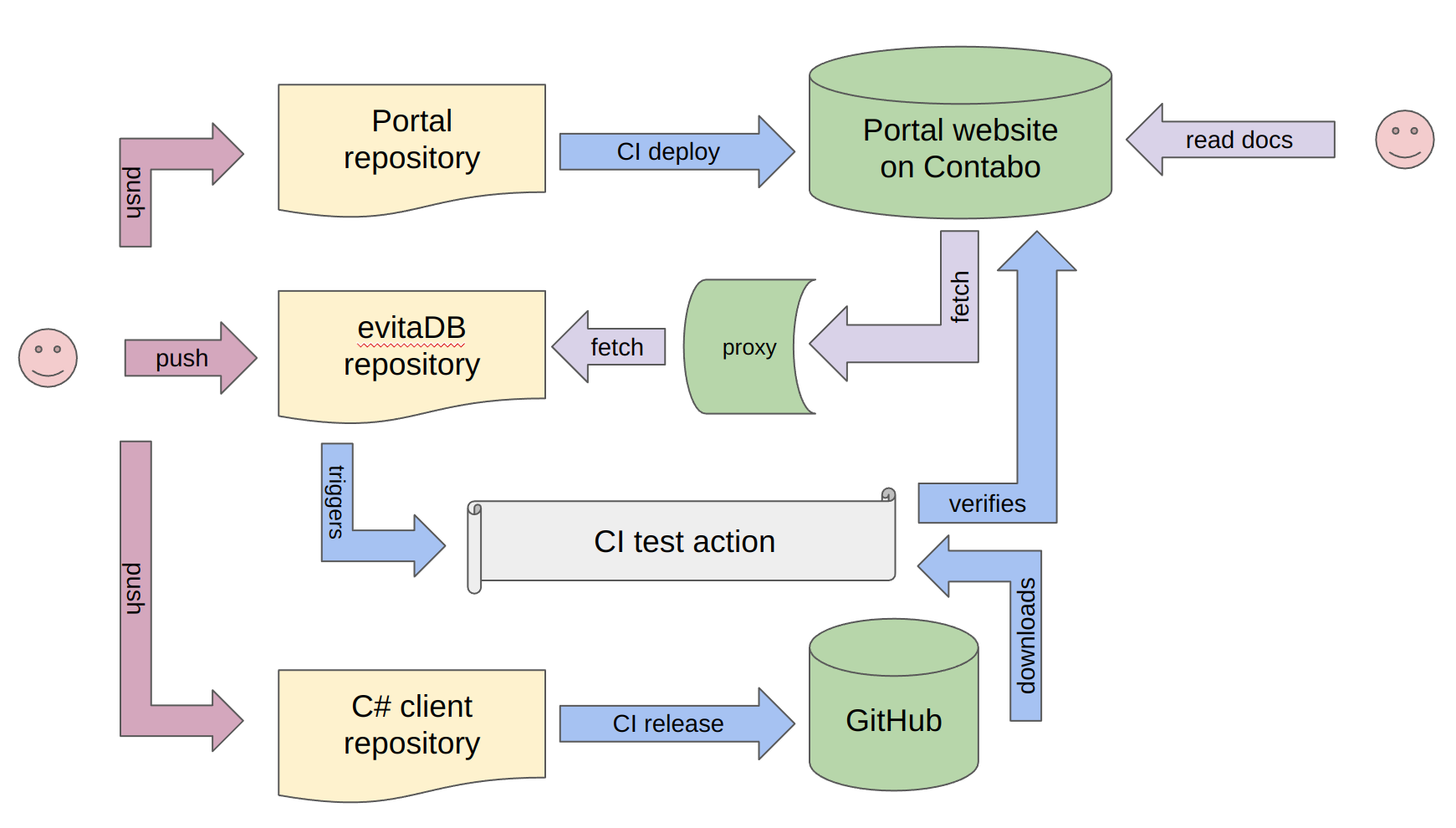 Component & activity pseudo-diagram
Component & activity pseudo-diagramAs you can see, it's quite a complex process, but it was worth it. We have found a number of bugs in API design and consistency across platforms. We have a safety net of end-to-end testing across our entire stack, which is a huge advantage when we want to refactor or change something.
Examples interactivity
Another cool feature of our examples is the ability to run them directly from the documentation portal. Just take a look at the video below:
Each example is stored in a separate file on GitHub and its location can be passed to an evitaLab instance running on the demo site, together with the evitaDB instance running on the demo dataset. The evitaLab instance then fetches the example from the GitHub repository, injects it into the code editor and automatically executes it against the demo dataset, displaying the result in a side panel.
In this way, the user can play with the example and modify it to see how it affects the result. We hope that this will help users understand the examples better and make it easier for them to get started with evitaDB.
Conclusion
We hope the portal will help us keep the documentation up to date and accurate, and make it more accessible to you. It has already fulfilled its purpose and helped us find a number of bugs in the API design and implementation and learn a lot of new things. We believe it provides a solid foundation for the future development of the documentation portal and evitaDB itself.
We look forward to your feedback and suggestions.
The article is based on a lecture at the Czech jOpenSpace unconference, which took place in October 2023. You can watch the recording of the lecture below (beware, it's in Czech):